

A data center project stays on track when one person ties IT load, building systems, and field work into one decision path. If I had to sum it up in plain English, I’d say this: the project manager keeps ownership clear, design and buying tied to one schedule, testing linked to turnover, and changes checked before they spread.
Here’s the short version:
If you want the simplest takeaway, it’s this: data center PM work is less about status meetings and more about decision control. When teams use the same schedule, the same risk view, and the same acceptance rules, go-live gets a lot less messy.
That’s the lens I’d use to read the rest of this topic.
Effective coordination is essential for mitigating schedule risks that often arise during complex facility builds.
Before design begins, turn the project brief into named owners and clear decision rules.
When IT, facilities, and construction are all working on one project, blurry ownership almost always leads to redesigns and messy handoffs. The PM's first job is to lock down scope, ownership, and decision rights before design moves ahead.
Before design starts, the PM should push the team to line up on capacity targets, growth phases, redundancy philosophy, and risk tolerance in one project brief. That brief should be tied to utility interconnection timing, long-lead equipment procurement, and regulatory and permitting milestones [3].
Data centers are tightly connected systems. Change IT load density, and that decision flows straight into cooling capacity, structural loads, and utility needs.
Owner approvals, utility interfaces, and permit cycles should be modeled as schedule activities with durations and logic ties inside the integrated master schedule.
Once the project brief is in place, the PM needs to turn it into clear ownership across the big decisions. A RACI matrix should assign one accountable owner for each major decision, and that owner should be named.
Focus first on the decisions that most often stall data center projects:
| Deliverable / Decision | Sponsor | PMO | Owner's Engineer | MEP Consultant | Operations |
|---|---|---|---|---|---|
| Load Basis (IT Capacity) | Accountable | Responsible | Consulted | Responsible | Consulted |
| Redundancy Target | Accountable | Consulted | Consulted | Responsible | Consulted |
| Utility Interconnection Application | Informed | Responsible | Consulted | Accountable | Informed |
| Commissioning Scripts | Informed | Responsible | Consulted | Consulted | Consulted |
| Handover Acceptance | Accountable | Responsible | Consulted | Consulted | Accountable |
Source: Adapted from AakashX Governance Model [2]
Facility operators should be consulted during design, not handed a finished product at turnover. Their input on maintainability, access, monitoring, and staffing needs can catch problems before the design gets locked in [2].
Governance only works when it has a steady rhythm. The PM should set a tiered cadence from the start:
Unresolved budget, redundancy, utility, and authority conflicts should move up to the steering committee, and every decision should be logged. Key roles in that group include the Project Sponsor, Finance/Commercial Owner, Facilities Head, Technology/Infrastructure Head, and Operations Head. End every meeting with a decision log [2].
With governance in place, the team can move into coordinated design and procurement.
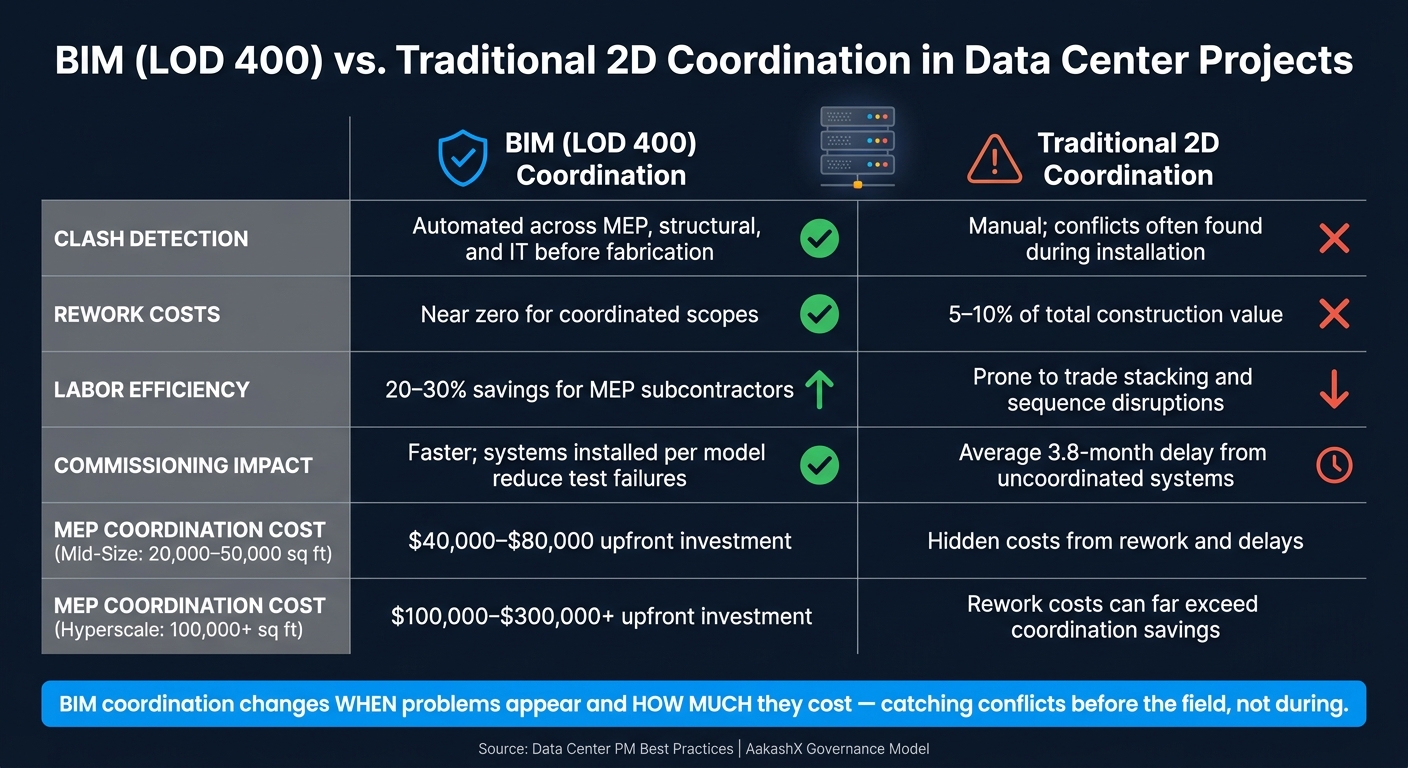
BIM vs. Traditional 2D Coordination in Data Center Projects
Next, the PM keeps design and procurement in sync across disciplines. Data center projects usually involve 15–20 specialized disciplines [8]. When those teams work in separate systems, design silos show up fast, and procurement starts to drift. Alignment only holds when IT, facilities, and construction teams use the same tools and follow the same schedule. Every review and approval also needs a named owner. If no one owns it, it tends to sit.
The most expensive clashes are the ones the team misses in the model and finds in the field. Common examples include cable trays running into chilled water mains and busway clearances conflicting with structural steel [4]. In dense data halls, those field-found clashes get expensive fast [4].
PMs should require LOD 400 models for mechanical and electrical scopes before field release. For a mid-size colocation facility of 20,000–50,000 sq ft, full MEP coordination at LOD 400 usually costs $40,000–$80,000. For hyperscale builds over 100,000 sq ft, that cost rises to $100,000–$300,000+ [4]. That spend helps stop mechanical and electrical choices from creating IT access or clearance issues later.
The day-to-day difference between BIM-led coordination and old-school 2D coordination is simple: it changes when problems appear and how much they cost.
| Feature | BIM (LOD 400) Coordination | Traditional 2D Coordination |
|---|---|---|
| Clash Detection | Automated across MEP, structural, and IT before fabrication | Manual; conflicts often found during installation |
| Rework Costs | Near zero for coordinated scopes | Typically 5–10% of total construction value [4] |
| Labor Efficiency | 20–30% savings for MEP subcontractors [4] | Prone to trade stacking and sequence disruptions |
| Commissioning Impact | Faster; systems installed per model reduce test failures | Average 3.8-month delay from uncoordinated systems [4] |
Each independently commissioned server hall should have its own coordination effort and its own clash detection rhythm [4]. Facility operators should also review the BIM model for access clearances and maintainability before design is finalized [2]. Problems left hanging at this stage don't stay small. They usually turn into procurement delays or installation slowdowns later.
A single integrated master schedule, or IMS, is what keeps design approvals, equipment deliveries, and IT activation from drifting apart. Every approval cycle should be treated like scheduled work: utility responses, permit reviews, owner approvals, and vendor clarifications all need durations and logic ties [7].
With utility power delivery running 1.5 to 2 years longer than expected [6], the interconnection path is almost always on the critical path. The IMS should show utility studies, interconnection approvals, and switching windows as separate schedule paths with named owners. Long-lead gear like switchgear, generators, UPS systems, and chillers should tie straight to design package release dates. They can't be left as assumptions. The schedule also needs room for submittal review loops and resubmissions. Assuming first-pass approval is a classic way to create late-stage schedule squeeze [7].
4D scheduling links the BIM model to the project timeline. That gives the team a way to see installation sequencing and check that systems are built in the right order of readiness [1][7]. The IMS should show more than when rooms are physically ready. It should show when IT installs can actually start. In practice, that means sequencing work by system readiness, not just by which trade is free next [1]. From there, the schedule drives vendor delivery, staging, and install sequence.
Even a solid schedule can fall apart when vendor handoffs aren't managed closely. The PM needs one procurement tracker that ties together submittal status, factory acceptance test (FAT) dates, delivery windows, and staging plans for every major equipment package.
A useful PM question is simple: which unresolved dependency can break the next milestone? That question tends to surface the handoff nobody has closed yet. FAT signoff requirements should be logged so results are formally recorded before equipment ships to the staging area [2]. Hardware should arrive in step with construction progress - not early, not late. When MEP, controls, and IT teams stay on the same delivery cadence, installation and commissioning keep moving toward turnover. When they don't, the gap usually shows up later during commissioning.
Once the equipment is on site, the PM has to do more than confirm delivery. The job now is to prove the installed systems work together before go-live. That means IT, facilities, and operations need to check power, cooling, controls, and network behavior as one system, not one after another, and not just on paper. At this stage, the PM moves from delivery control to functional proof.
Commissioning should start during design and procurement. FAT, SAT, pre-commissioning, and integrated systems testing (IST) need to be built into the master schedule and written into vendor scopes. By the time equipment reaches the site, the testing sequence should already line up with construction completion dates and IT activation windows.
The integrated systems testing (IST) phase is where coordination gets tested for real. This is when the team runs failure-event scenarios such as a total utility power loss, UPS transfer, generator start and load acceptance, chiller failure, and fire suppression interlock logic. Contractors, the commissioning agent, facilities staff, controls teams, IT leads, and operations staff all need to be in the room to verify what happens.
That last group matters a lot. Operations staff should watch these tests firsthand so they don't meet the facility's behavior for the first time after turnover.
If failover, controls, and operations drills are not witnessed and signed off, the facility is not ready for turnover.
Readiness needs to be tracked in a way the whole team can use. That includes equipment IDs, test scripts, witness sign-offs, and open deficiencies by room and system. Each deficiency, sign-off, and test result ties straight to turnover readiness, so the tracker isn't just a status log. It's an operations-control tool.
BMS and DCIM checks belong here too. Point-to-point sensor mapping, alarm threshold approvals, and escalation logic all need to be verified, not assumed.
| Punch-List Severity | Meaning | Turnover Impact |
|---|---|---|
| Critical | Unsafe condition or failure of a critical function | Blocks turnover |
| High | Affects redundancy, reliability, or monitoring | Usually blocks turnover unless formally risk-accepted |
| Medium | Operational inconvenience or incomplete non-critical function | May allow conditional turnover |
| Low | Documentation, labeling, or cosmetic issues | Closed post-turnover |
Critical and High items should stay open until there is retest evidence. That's what stops a team from accepting a facility that looks ready but still has gaps.
Once readiness is visible, the PM can sequence operational cutover without guesswork.
After commissioning closes, the PM shifts into cutover and turnover planning. IT cutover needs its own sequence. Rack installs, cable pulls, network bring-up, and energization windows should be planned in order, especially in partially live sites where a change freeze is in effect. If permanent cooling is not fully commissioned but IT equipment is about to be powered up, temporary cooling plans need to be ready.
SOPs, MOPs, EOPs, and operator training are there so the facility can run on day one, not so people can figure it out as they go. As-builts, O&M manuals, SOPs, MOPs, EOPs, training records, asset registers, and the validated monitoring dashboard should be finished during commissioning, not pushed into the final week.
Once commissioning shows the systems work, the PM’s job shifts. Now the goal is to protect the baseline through change control and phased turnover. At this stage of a data center build, the biggest threats often come from poor coordination: changes no one fully reviewed, dependencies no one logged, or turnover that happens before operations is set to take over. Tight change control and a clear handover process help stop those problems before they spread.
Late-stage changes in data center projects almost never stay small. A move to higher rack density can ripple across the floor layout, cooling load, UPS and generator sizing, and cable management. That’s why every change needs a documented cost, schedule, and technical impact before approval, not after. [2]
Some of the worst risks show up at the handoff points between teams. For example, IT rack installs may stall because electrical room work isn’t done. Or commissioning scripts may fail to run because EPMS control points are still missing. Those interface risks need their own log so they don’t disappear inside the general register. [2]
Use the risk register for likely events. Use the issue log for active problems. That simple split helps the team act early, before risks turn into issues. [2]
With change control in place, the PM can turn over each area in planned phases. That matters because data center turnover often happens in stages. Main mechanical rooms, electrical rooms, and support spaces may transfer while nearby construction is still going on. That can work, but only when each phase has clear acceptance gates before the keys change hands.
Those acceptance thresholds should cover four items:
If even one gate is missing, the space is not ready for turnover. [9]
This is what alignment looks like through final turnover. Strong PM coordination on a data center build is not about holding more meetings. It’s about making sure every decision - on design, procurement, commissioning, and change - has a documented owner, a clear impact check, and a verified close-out.
"Data center project governance fails when the project is treated as a reporting exercise instead of a decision-control system." - Aakash Ahuja, Founder of ITMTB [2]
The table below shows the difference in day-to-day project results:
| Metric | Uncontrolled Change Management | Structured Change Management |
|---|---|---|
| Schedule Variance | High; reactive to late-stage field conflicts | Low; predictive via Time Impact Analysis (TIA) [5] |
| Budget Variance | Unpredictable; frequent contingency depletion | Controlled; changes tied to documented cost impacts [2] |
| Post-Go-Live Incidents | High; due to unverified informal site changes | Low; all changes verified through commissioning [2] |
| Unplanned Outages | Common; failure scenarios not proven during IST | Rare; failure scenarios proven during IST [9] |
The projects that hit their go-live dates and stay stable usually have one thing in common: IT, facilities, and construction are working from the same schedule, the same risk log, and the same acceptance criteria from design through final turnover.
A data center project manager should bring operations teams in during the initial design phase and keep them involved for the full project lifecycle.
That early involvement makes a big difference. It helps bake operational needs - like maintainability, incident readiness, and staffing - into the design and construction plan from the start. And that helps avoid handoff gaps when the site moves into live operations.
Data center project delays often start with teams not lining up and decisions getting made in silos. In a tightly linked project, one design change - or one missed dependency - in mechanical, electrical, or IT systems can ripple into other areas and slow down the critical path.
The usual trouble spots are pretty familiar: late redesigns, long-lead equipment procurement problems, delayed utility responses, weak handoffs between commissioning and operations, inconsistent scheduling logic, unclear escalation paths, and communication gaps.
Phased turnover gives operators a way to bring selected data halls or entire buildings online while work keeps moving in other parts of the campus. The whole approach relies on tight sequencing. Teams build, test, and commission systems in stages so new capacity comes online in steady, predictable increments.
Project managers need to make sure the electrical and mechanical systems for each phase are fully energized and commissioned before any IT equipment goes in. A room that looks finished isn’t enough. There has to be a clear separation between live operational space and active construction zones to protect uptime.








