

Mission-critical jobs fail when teams track install progress but miss system readiness. If I had to sum up the article in one line, that’s it.
On data centers, hospitals, power sites, and advanced plants, the job is not done when the space looks finished. It’s done when the system can be tested, commissioned, and handed over without drama. That changes how I would plan the work, staff the team, and track risk from day one.
Here’s the short version:
A few facts make the point fast:
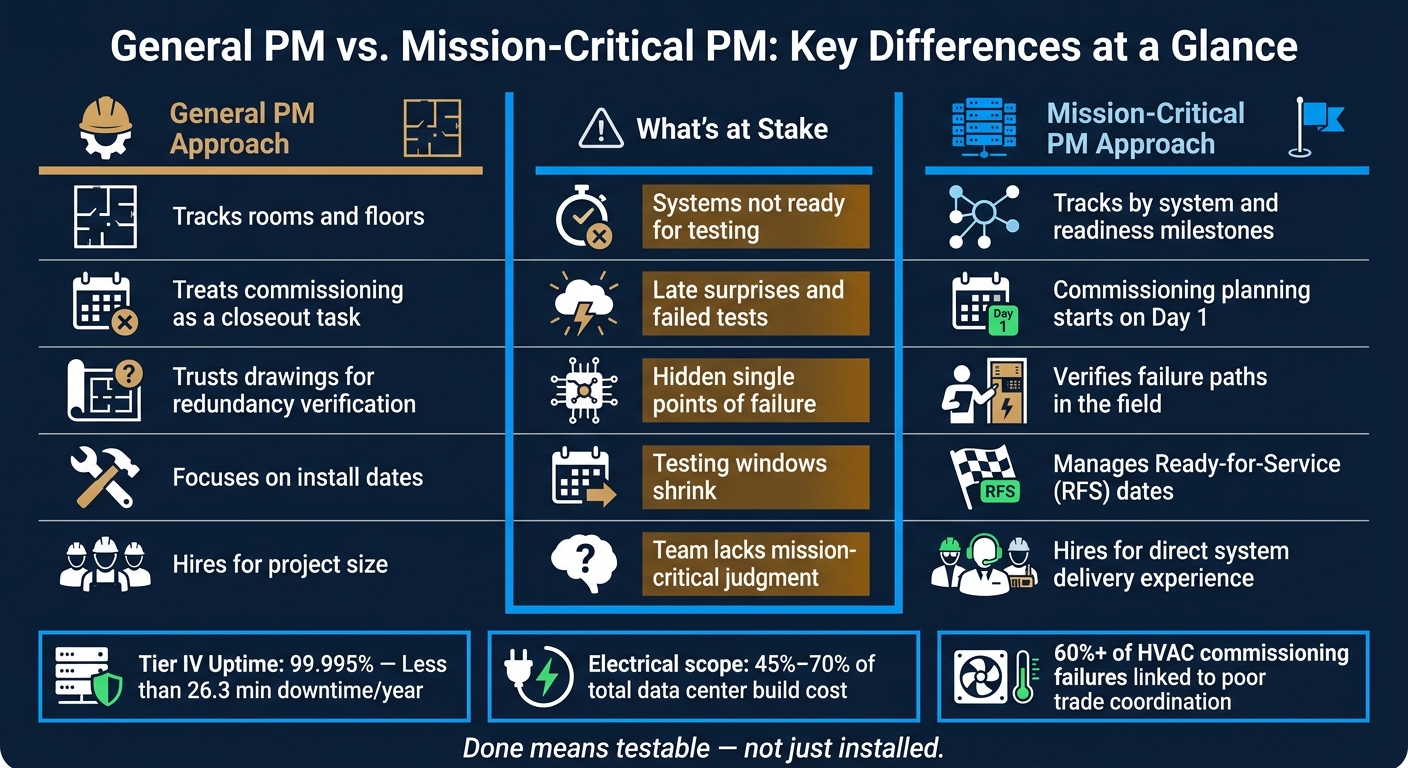
General PM vs. Mission-Critical PM: Key Differences at a Glance
| General PM habit | What goes wrong | Better mission-critical approach |
|---|---|---|
| Track rooms and floors | Systems are not ready for testing | Track by system and readiness |
| Treat commissioning as closeout | Late surprises and failed tests | Start commissioning planning early |
| Trust drawings on redundancy | Hidden single points of failure stay in place | Check failure paths in the field |
| Focus on install dates | Handoffs slip and testing windows shrink | Manage readiness milestones |
| Hire for project size | Team lacks mission-critical judgment | Hire for direct system delivery experience |
If I were reading this as an owner, builder, or hiring manager, my takeaway would be simple: mission-critical work needs a different playbook. The risk is not just finishing late. The risk is reaching turnover with systems that still cannot prove performance.
Habits that work on office or warehouse jobs can create risk on mission-critical work. The gap usually shows up in three places, and the pattern is pretty consistent.
A lot of general PMs are trained to judge success at substantial completion. On mission-critical jobs, that mindset falls short. Here, success means systems perform under load and redundancy works the way the design says it should [2].
Take a 2N UPS system. On paper, it should deliver a fully mirrored critical load path. But one shared distribution whip can introduce a hidden single point of failure inside a setup that looks redundant in drawings and reports [2]. That's the kind of detail that can sink a job after everyone thought the hard part was done.
The uptime target makes the stakes obvious. Tier IV data centers aim for 99.995% uptime - that means fewer than 26.3 minutes of allowable downtime per year [2]. With margins that tight, unresolved single points of failure can't sit on a punch list for later.
And that same miss tends to show up again in commissioning.
Commissioning isn't just a closeout item. It runs from factory acceptance testing through integrated systems testing, and every stage depends on upstream readiness being checked and confirmed [2]. If a PM waits too long to plan pre-functional checks and functional performance testing, the whole sequence gets squeezed into the back end of the schedule.
"Commissioning usually doesn't fail at the end. It reveals what was never truly ready upstream." - David Locke, BridgeView IT [6]
That quote gets right to the point. The issue often isn't the final test itself. It's everything that wasn't lined up before the test started.
The data backs that up. Poor coordination between trades is cited in over 60% of commercial HVAC commissioning schedule failures [6]. When readiness isn't verified upstream, commissioning turns into live troubleshooting. Instead of proving system performance, technicians spend their time tracking down installation mistakes and fixing field issues [6].
Area-based sequencing can work on many building types. On mission-critical work, it often breaks down when MEP, controls, startup, and TAB all need to line up around actual system readiness [5].
That matters for a simple reason: electrical systems make up 45% to 70% of total construction costs in data centers [2]. On top of that, switchgear and other heavy electrical assemblies can come with lead times of 8 to 24 months [2]. So when procurement slips, or one handoff lands late, the damage doesn't stay local.
A dashboard may still look fine for a while. Install progress can appear healthy. But the job can already be drifting into a state where testing becomes impossible on time and recovery gets expensive [3].
This is where loose handoffs do real harm. If the transitions between mechanical, electrical, startup, TAB, and controls aren't clearly defined, the controls team usually ends up absorbing the delay. Then the testing window gets squeezed, and everyone starts paying for time twice [6].
The fix is simple in concept, even if it's hard in practice: manage readiness milestones, not just install dates.
The last section covered where projects go off the rails. This section is about what to change - before the first shovel hits the ground.
On mission-critical work, the schedule needs to follow the critical power path: utility feed → medium-voltage switchgear → ATS → generators → UPS → PDUs [2]. If one link in that chain slips, everything after it slips too.
That changes what the team should watch most closely. It’s not area completion. It’s the Ready-for-Service (RFS) date: the point when the facility is energized, commissioned, and accepted by operations [2]. Turnover should be tracked by system, so testing starts only when each path is ready.
Pull-planning helps teams work backward from startup milestones and spot handoff gaps early [1]. But that only works if every handoff is visible before the schedule starts sliding.
Commissioning control should start on day one with an equipment-level tracker, a risk register, and a turnover plan. That’s not overkill. It’s basic control on this kind of job.
Switchgear, generators, and UPS modules now carry lead times of 8 to 24 months [2]. Because of that, procurement has to sit inside the Integrated Master Schedule, not off to the side [3].
This is one of the biggest differences between a conventional PM approach and a mission-critical one. A conventional PM may track area completion. A mission-critical PM tracks system readiness, long-lead gear, and verification milestones. That’s how teams catch readiness gaps before they turn into outages, rework, or failed acceptance.
Done means testable, not just installed [3].
Facilities, IT, clinical, or manufacturing operators should be part of readiness reviews throughout construction, not just at turnover [1]. When those people are in the room early, they surface requirements before those issues turn into project risk.
That early feedback loop - between field teams, commissioning agents, and the operations team - is often the difference between a project that hits its RFS date and one that misses it.
These controls only matter if the PM knows how to run them, which is why the next step is hiring for mission-critical experience, not just project size.
Tools help, but they don't make up for field time. For mission-critical hiring, look for PMs who have already delivered these systems in live project settings, not just people who have run big commercial jobs.
Project size, by itself, doesn't tell you much. A better test is whether the candidate has dealt with the exact problems that derail mission-critical work: commissioning delays, MEP coordination misses, and turnover breakdowns. Those are the pressure points.
Look for direct experience with long-lead procurement tied into the master schedule, including switchgear, UPS modules, and generators [2]. You also want someone who has worked through commissioning from pre-functional checks to integrated systems testing and turnover.
A simple interview question can reveal a lot: ask how they handled a delayed piece of critical gear, and what that delay did to commissioning. That answer says more than a polished resume ever will.
Certifications can help with screening, but they shouldn't do the thinking for you. Put more weight on credentials that match the role and the systems in play. If a candidate can speak clearly about concurrent maintainability (Tier III) and fault tolerance (Tier IV), there's a good chance they've worked in places where those limits were actual job constraints, not just terms they memorized.
Most mission-critical projects need more than one general PM. The MEP scope is large, commissioning is its own discipline, and the schedule leaves very little room for drift.
| Role | Primary Focus | Key Risk Mitigated |
|---|---|---|
| Commissioning Manager | L1–L5 systems verification | Failed integrated systems testing and turnover delays |
| MEP Manager | Mechanical, electrical, and plumbing coordination | Routing conflicts and late-stage coordination failures |
| Controls Lead | BMS/EPMS integration | Misalignment between mechanical and electrical logic |
| Project Controls Lead | Schedule and cost discipline using Primavera P6 | Drift that becomes delay |
| QA/QC Manager | Inspection program and punch list | Failed handoff from construction to commissioning |
These roles shouldn't be treated as late hires. A staffing gap at the front end often turns into an execution gap once commissioning starts.
When the schedule is tight, normal hiring channels often move too slowly. Mission-critical hiring needs a narrower screen built around the role itself. Put focus on candidates who have worked under zero-downtime constraints, managed long-lead equipment, and understood from day one that commissioning drives the schedule [1][4].
The interview process should test whether the person can deliver at the system level, not just whether they've been attached to large projects. The strongest candidates can point to zero-downtime delivery and hands-on commissioning leadership, not just a long list of project names.
Most mission-critical failures begin in planning. That’s the moment when standard assumptions run headfirst into work that leaves no room for error. So the planning model has to change before the job begins.
The fix isn’t complicated: change how the project is planned. Operational readiness, not physical completion, is the measure of success. In plain terms, the job should be planned around systems, commissioning, and operations readiness from day one, not treated as a handoff issue at turnover.
And once the delivery model changes, the team setup has to change too. Hiring for mission-critical roles follows that same logic. Commissioning managers, MEP managers, controls leads, and project controls leads need a seat at the table early. They can’t be brought in later after issues show up. A staffing gap at the front end almost always turns into an execution gap when commissioning starts.
If the project has no room for failure, the team can’t be built for average risk.
Commissioning should begin in the design phase, long before construction starts.
Bringing the commissioning team in early gives them time to stress-test the design, check whether systems can be tested in practice, and spot failure points on paper before they turn into expensive jobsite problems. It also helps make sure day-to-day operations, maintenance access, and system integration are built into the plan before turnover.
Readiness milestones are measurable, logic-driven checkpoints that show a system is ready for its next testing or operating phase, not just marked complete on paper.
In mission-critical construction, they help stop execution gaps from slowing down commissioning. Good milestones rely on formal criteria, signed checklists, verified prerequisites, and named owners. Teams usually review them 3 to 4 weeks before startup.
Focus less on broad construction backgrounds and more on deep skill in MEP coordination, systems integration, and commissioning.
The best candidates usually bring hands-on knowledge of N+1 redundancy, high-voltage design, FAT, SAT, and IST. They also need the kind of systems thinking that helps them manage long-lead equipment, line up dependencies across teams, and keep the critical path moving all the way to Ready-for-Service.
Start early. Demand is high, and the talent pool is tight.








